| promo |
|
| продвижение сайтов в поисковых системах трафик, позиции, прозрачность | |
Переформулировки поисковых запросов в Яндексе
Евгений Трофименко
ноябрь 2010
доклады
Доклад на конференции
"Поисковая оптимизация и продвижение сайтов в Интернете 2010", Москва, 10-12 ноября 2010 (презентация)
"Продвижение сайтов в белорусском интернете, SEO Революция 2010", Минск, 17-19 ноября 2010 (презентация, расшифровка текста)
(файл)
Расшифровка текста доклада на searchengines.ru
Просмотреть презентацию в браузере?
Введение
В данной работе рассмотрены результаты, полученные из одной «недокументированной фичи» - показа в Яндекс.XML запроса, который реально отрабатывает вместо введенного пользователем. Эта возможность позволяла получить информацию о дополнительных словах в переформулированном запросе, контрастностях слов и ограничении расстояний между словами при поиске.
Расширение пользовательских запросов в Яндексе
Введенный пользователем запрос подвергается определенным изменениям перед отработкой его поисковой машиной (историческое название «переколдовка»), изменения могли включать в себя и добавление новых слов. Например, запрос что такое XYZ изменялся таким образом, что в запрос добавлялись слова это, означает, аббревиатура, расшифровывается, которые также подсвечивались в выдаче. Однако, если раньше это делалось в единичных случаях, то теперь поисковик находит подходящие переформулировки для большого количества запросов – вручную или автоматически – вопрос отдельный.
Летом 2008
года Яндекс сообщил [7] об изменениях в алгоритме переформулировки запросов,
которые предполагают сильные изменения, включающие автоматическое добавление
новых слов в запрос:
Одну и ту же поисковую потребность пользователь может выразить разными
запросами. Например, запрос «гамбургские гостиницы» кажется эквивалентным по
смыслу запросу «гостиницы Гамбурга».
***
Теперь поиск Яндекса (версия «Магадан») еще учитывает следующие
отношения:
а) некоторые типы переходов из одной части речи в другую («гамбург»
-> «гамбургский»);
б) транслитерация («mazda» -> «мазда»);
в) аббревиатуры (МГУ -> Московский государственный университет).
Как именно происходит эта переформулировка запроса? Во-первых, некоторые слова могут быть заменены по смыслу (в случае замены транслитерации или аббревиатуры). Во-вторых, в некоторых случаях запрос может быть расширен с переходом между частями речи (недвижимость в Москве -> московская недвижимость, продвижение сайта – продвигать сайт).
Важно не только знать, какие именно слова и расстояния находятся в переформулированном запросе, но и каким именно образом «внутри» Яндекса отрабатывают эти переформулировки.
Если переформулировка происходила бы с использованием оператора «ИЛИ», то, вероятно, разные варианты слов почти не «пересекались» бы в подсчете релевантности. Например, могло оказаться, что дополненный/измененный запрос -- низкоконкурентный и более легкий для продвижения. Тогда, установив особенности подмешивания выдачи по одному запросу к результатам другого, мы найдем возможности оптимизации бюджета продвижения.
Если же дополнительные слова дают дополнительный вклад в релевантность, их имеет смысл использовать в текстах и ссылках наравне с основными словами запроса.
История изменений
Изначально в «переколдовке» запросов были доступны данные о дополнительных словах, расстояниях между словами и «весах» слов. Однако, Яндекс последовательно борется с возможностями получения информации.
В 2008 году [3], [4] был доступен метод определения ограничений расстояния между словами с помощью операторов исключения вида:
(+слова +запроса) ~~ (+слова [ОПЕРАТОР_РАССТОЯНИЯ] +запроса)
Перебирая различные операторы расстояния, можно было добиться ситуации, когда в результатах Яндекс.XML-поиска, где показывалось отдельно число найденных документов в пределах контекстных ограничений (strict) – оно обнулялось при увеличении подобранного расстояния между словами:
<found
priority="phrase">0</found>
<found
priority="strict">0</found>
<found
priority="all">7813345</found>
И подобранное таким образом расстояние соответствовало истинному расстоянию между словами. Однако, в настоящее время Яндекс.XML «вылечил» эту возможность и перестал давать разное число найденных документов для relevance priority = phrase, strict, all:
<found
priority="phrase">7786843</found>
<found
priority="strict">7786843</found>
<found
priority="all">7786843</found>
Поэтому теперь подбор расстояний таким образом невозможен, можно только пользоваться архивными данными. То, что данные по числу страниц показываются заведомо неверные – видимо, стало новой его «фичей». :)
Показ переформулированных запросов в Яндекс.XML
Летом 2010 мной случайно была обнаружена интересная возможность [11] – при задании определенного вида запросов в Яндекс.XML в ответном результате появлялись данные следующего вида, по запросу поисковая оптимизация:
((поисковая::17483 ^ поисковик::65545) &&/(-32768 32768) (оптимизация::32653 ^ оптимизировать::95157 ^ оптимизироваться::4208069))
Это происходило, как представляется, в результате ошибок в модуле подсказок в ответ на опечатки в поисковом запросе. Например, при задании запроса вида
(fizi-olog) (поисковая оптимизация)
(fizi-olog) – воспринимался как не одна ошибка, а сразу две – Volapyuk (транслит запроса) и Undash (что-то с разбиением слова на части). В результате в подсветке результата появлялась подсказка такого вида:
<reask>
<rule>Undash</rule>
<source-text/>
<text-to-show/>
<text>(fizi::61543020-olog::1234567) ((поисковая::17483
^ поисковик::65545) &&/(-32768 32768) (оптимизация::32653 ^
оптимизировать::95157 ^ оптимизироваться::4208069))
</text>
</reask>
…которая и содержала (очевидно) переформулированный запрос.
Однако, эта подсказка появлялась только в том случае, когда в выдаче найден хоть один результат, а это происходило далеко не всегда. Поэтому я пошел двумя путями – сделал свой экспериментальный массив, содержащий рабочие «ошибочные» слова вместе со всеми словами русского языка и собрал коллекцию из ~20 тыс. «воляпюков».
В результате удалось выкачать ~1.3 млн. разных переформулировок по популярным поисковым запросам. Хотя я и скрывал метод получения, Яндекс нашел и прикрыл эту возможность, поэтому о методе теперь можно и рассказать. :)
При введении «переформулированного» запроса как исходного результаты выдачи изменяются. Это может быть связано как с дополнительным переформулированием уже переформулированного запроса, так и с изменениями в обработке «весов» слов.
Данные по переформулировкам доступны в сервисе [1], веса слов доступны в сервисе [2].
Оператор [^]: [|] или [%]?
Наиболее интересной особенностью переформулированных запросов является перечисление дополнительных слов запроса через оператор ^.
Как работает этот оператор – нужно выяснять дополнительно. С одной стороны, он дает результаты, похожие на работу оператора [%] - с необязательным включением дополнительных слов при обязательном основном слове. С другой стороны, в выдаче иногда встречаются результаты, не содержащие основного слова запроса. С третьей стороны, на классический оператор «ИЛИ» [|] он тоже не похож – результаты выдачи значительно отличаются и, в отличие от «или» меняются при «перемене мест слагаемых» (в зависимости от того, какое слово идет первым до ^, а какое после него).
В любом случае, основной вопрос – дают ли дополнительные слова в переформулированном запросе вклад в релевантность или считаются полностью независимо. Я остаюсь при мнении, что дают, и что оператор ^ дает приоритет основному слову запроса и работает похожим на % образом.
Особенности переформулировок
Все переформулировки содержали «веса» слов, более половины переформулировок содержали расширение запроса дополнительными словами, около 10% содержали ограничение расстояния между словами.
Особенности переформулировки полностью соответствуют предыдущим наблюдениям – очень часто стало использоваться «длинное» расстояние между словами, как в приведенном примере – 32768 предложений.
Новые части речи, транслит, расшифровка аббревиатур – как и ожидалось, активно используются. Часто используются возвратные глаголы («продвигаться» наравне с «продвигать»), аббревиатуры расшифровываются с прямым порядком слов с расстоянием «плюс-минус одно слово» медлу соседними словами.
Общее количество переформулированных сложным образом запросов довольно велико – более 70% процентов от всей базы. В принципе, и раньше «переколдовок» было много – видимо, автоматическое расширение запросов имело место и тогда, и сейчас.
| оператор | доля от 1.3 млн. | пример переформулировки | |
| классическое "ИЛИ" | | | 0.72% | (dsl::91438 &/(-1 1) 200::4936) | dsl200::709103565 |
| расширение запроса дополнительными словами | ^ | 64.10% | одноклассники::38226 ^ odnoklassniki::734294 ^ одноклассница::650388 |
| поиск в пределах соседних слов | &/ | 11.38% | adobe::18994 &/(-1 1) illustrator::192273 |
| все словоформы | !! | 10.51% | google::6272 ^ !!гугл::54546428 |
| поиск имен и фамилий | fioname[] и др. | 2.43% | (александр::4275 ^ aleksandr::259060 ^ alexander::68471 ^ alexandr::278003 ^ саня::142275) &&/(-32768 32768) рыбак::58640) ... (fioname[((александрfi::5221 &&/(-32768 32768) рыбак::58640))] | fiinname[((аfi::1059 &&/(-32768 32768) рыбак::58640)) |
| разбиение на фрагменты | 7.11% | youtube::15650 ^ ((you::272-tube::11492)) |
Если дополнительные расширяющие запрос слова и можно найти в открытой выдаче, то с расстояниями все гораздо сложнее. Яндекс последовательно борется с возможностью получения внутренней информации о переформулировках.
Транслитерация запроса
ютуб
ютуб::956008
^ utube::6608646 ^ yutub::27352453 ^ ((ю::7853-туб::342977))
hyundai
hyundai::93536
^ !!хюндай::70910356 ^ !!хендай::709103565
Ограничения расстояний между словами – 10% запросов
Часто используются привычные нам расстояния, ставшие уже классическими – в одно слово, в три и семь предложений:
в контакт
!(+в::51 &/(-1
1) контакт::19088
рабочий
стол обои
рабочий::4494
&/(-1 1) стол::6379 &&/(-32768 32768) обои::7086
русская
страховая компания
((русская::1225
^ русско::49342) &/(-1 3) ((страховая::19855 ^ страховка::74092 ^
страховщик::125678 ^ страхование::12393) &&/(-32768 32768)
компания::923) ^ ск::55022) ^ !рск::1487444
театр
юного зрителя
((театр::9046
^ theatre::57479 ^ театральный::46013) &&/(-32768 32768) юного::31141 &/(-1
3) зрителя::30667) ^ тюз::928951
налоговая
46
(налоговая::12044
^ налог::10340) &/(-3 3) 46::3495
6300
nokia
6300::270856
&/(-3 3) nokia::12493
нормативные
документы дополнительного образования
нормативные::20026
&/(-1 1) документы::3472 &&/(-7 7)
дополнительного::4085 &&/(-7 7) образования::3396
Работа с фрагментами слов
Часто используется разбиение длинных слов на фрагменты и разбиение сложных обозначений из букв и цифр:
Составные слова:
кинопоиск
кинопоиск::192359
^ kinopoisk::830960 ^ ((кино::4292-поиск::775))
билайн
билайн::46541
^ beeline::224866 ^ ((би::45262-лайн::28714))
Сложные обозначения могут искаться почти во всех возможных вариантах разбиений
w200i
w200i::4958766 ^ (!(w::1737 &/(1 1) 200::5303 &/(1 1)
i::199)) ^ ((w200::633693 &/(1 1) !i::199)) ^ ((!w::1737 &/(1 1)
200i::23636785))
Используется не только разбиение, но и склейка популярных фрагментов в одно слово:
dsl 200
(dsl::91438
&/(-1 1) 200::4936) | dsl200::709103565
Курьезы переформулировок запросов
В пользу автоматического подхода Яндекса к подбору переформулировок кроме общего большого количества переформулированных запросов говорит еще и то, что зачастую переформулировки встречаются явно бессмысленные. Например, по запросу витрины москва вместо «витрин» находятся сайты с «окнами» [10]
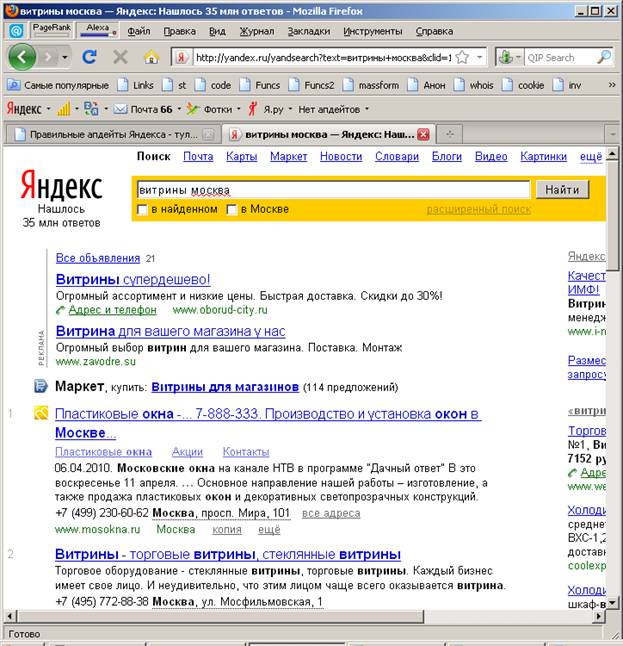
То, что это не глюк, а фича - подтверждается исключением слова «витрина» из запроса – в этом случае в выдаче остаются только «окна». Витрина, конечно, тоже может быть сделана из стекла, однако сложно представить, что человек может назвать витрину окном – вероятно, тут «поработал» алгоритм.
С другой стороны, некоторые другие примеры переформулировок явно показывают вмешательство человека. Например, запрос партия единая россия переформулируется как
партия
единая россия
(партия::10385
&&/(-32768 32768) ((единая::10481 &/(-1 3) россия::827) ^ ер::234393)
^ !!едро::2480323) ^ !!педирос::492344160
По данным http://wordstat.yandex.ru/
Что искали со словом «педирос» — 24 показа в месяц.
Мне лично не верится, что алгоритмы Яндекса способны на такие расширения запросов, тем более непопулярными словами, которые редко задаются в поиске и статистика использования слов в запросах вряд ли может помочь. :)
Новые поисковые зоны и термы в большом поиске (ФИО)
Кроме расширений запросов дополнительными словами, в переформулировках видны также новые операторы поиска и термы, соответствующие поиску по именам. Для запросов, содержащих имена в виде нескольких слов, например:
вася пупкин
Переформулировка содержала фрагмент вида:
fioname[((васяfi::332552
&&/(-32768 32768) !!пупкин::901729))] |
fiinname[((вfi::1574
&&/(-32768 32768) !!пупкин::901729))] |
fiinoinname[((вfi::1574
&&/(-32768 32768) !!пупкин::901729))] |
finame[((васяfi::332552
&&/(-32768 32768) !!пупкин::901729))]
Здесь мы видим новые операторы поиска по новой поисковой зоне, соответствующей имени
fioname, fiinname, fiinoinname, finame
Кроме этого, в запросе присутствуют отдельные термы термы (вfi, васяfi) – поиск всех имен, которые начинаются на фрагмент, стоящий перед fi и в сокращенном варианте тоже. Например, если задать запрос вfi:
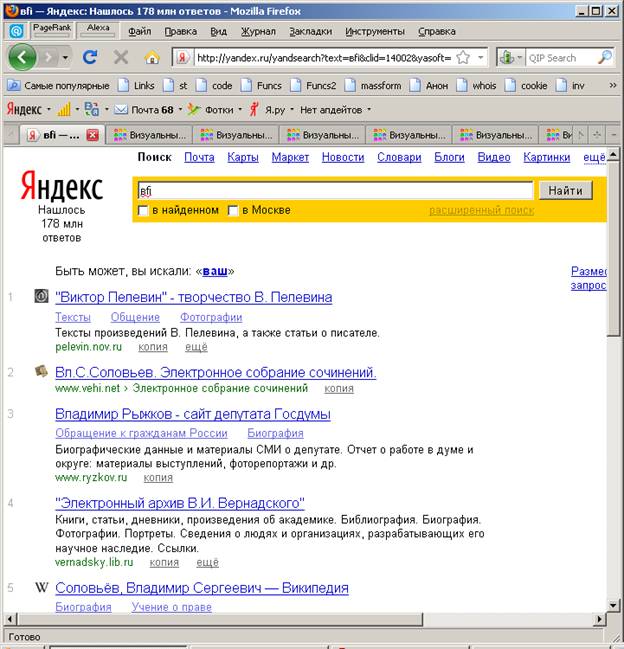
Мы найдем результаты, в которых будут все имена, начинающиеся на В, в том числе и сокращения (пример здесь: В.И.Вернадского, Вл.С.Соловьев)
Использование новых поисковых зон и отдельных термов показывает нам, что выделение сущностей (например, имени) – в большом поиске Яндекса уже началось и уже внедрено. Яндекс начал в боевом режиме использовать выделение объектов без специальной разметки и микроформатов.
«Веса» слов (контрастность по общей базе)
Вес, который используется и использовался при переформулировках через двойное двоеточие после слова – является мерой контрастности, заметности этого слова в общей базе слов. Очень популярные и стоп-слова имеют низкий «вес», редкие слова – наоборот, высокий вес. Как правило, слова с низким весом стараются использовать как дополнительные для разбавления текстов ссылок. А насколько на самом деле одно слово «весит» больше, чем другое?
Связь «двоеточечного веса» с классическим IDF (Inverse document frequency)
Часто можно услышать употребление термина «IDF» в отношении этого двоеточечного веса. Однако некоторые особенности дают повод для сомнений в правильности этого.
Веса, которые наблюдались раньше и присутствуют в переформулировках, обладают некоторыми особенностями, например – эти веса не непрерывны, есть фиксированный набор популярных значений весов, также существует некий «максимальный» вес слова по коллекции.
В таблице приведен набор самых больших весов слов по части коллекции с небольшой статистикой:
| ::вес | слов | отличие, раз |
| 984688320 | 2080 | 1 |
| 492344160 | 302 | 2 |
| 328229440 | 206 | 3 |
| 246172080 | 197 | 4 |
| 196937664 | 148 | 5 |
| 164114720 | 169 | 6 |
| 140669760 | 130 | 7 |
| 123086040 | 123 | 8 |
При этом топовые веса, что интересно, кратны максимальному весу (984688320) и получаются делением его на целое число. Однако, в формуле классической IDF используется логарифм, и никаких целочисленных отношений (кроме как в 10, 100… раз) быть не может:
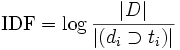
|D| — количество документов в корпусе;
![]() —
количество документов, в которых встречается ti
—
количество документов, в которых встречается ti
Однако по базе реальных весов целочисленное соотношение – скорее правило. По виду формулы IDF становится очевидно, что вес – это отношение D/Di до логарифмирования.
Т.е., общее число документов в коллекции D = 984688320, самое редкое слово встречается в коллекции 1 раз, и Di=1. Второе по редкости слово встречается в коллекции 2 раза, и D/Di=(984688320/2)=492344160 и так далее.
Таким образом можно сделать вывод, что двоеточечный вес – это вовсе не IDF, а IDF получается взятием логарифма от веса:
::вес=Dобщее/Dсо словом
IDF=log(::вес)
Если в Яндексе для взвешивания слов используется классическая IDF, отличия в контрастности слов получаются не столь разительными:
| ::вес | слов | отличие, раз | IDF |
| 984688320 | 2080 | 1 | 8.993299 |
| 492344160 | 302 | 2 | 8.692269 |
| 328229440 | 206 | 3 | 8.516178 |
| 246172080 | 197 | 4 | 8.391239 |
| 196937664 | 148 | 5 | 8.294329 |
| 164114720 | 169 | 6 | 8.215148 |
| 140669760 | 130 | 7 | 8.148201 |
| 123086040 | 123 | 8 | 8.090209 |
Связь «двоеточечного веса» с мерой по словоформам (ICF)
То, что веса рассчитываются по числу документов, содержащих слово, а не по общему числу словоформ в базе – это еще большой вопрос. Похожие результаты можно получить, если использовать вместо D общее число слов в коллекции и вместо Di – число выбранных слов. Дополнительно следует отметить, что вес точной формы слова отличается от сыммарного веса всех его словоформ – это было видно и в переформулировках.
Для примера рассмотрим связь истинных весов слов из переформулировок с числом слов (не документов, а словоформ) в базе Яндекса:
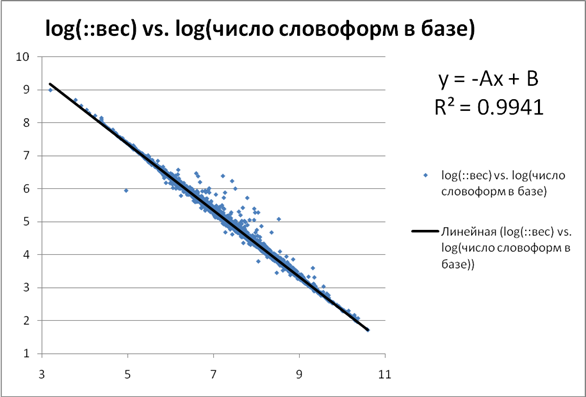
Видно, что это практически точная линейная зависимость без отклонений в области малых весов (популярных слов).
Если бы ::вес был документным, то в области малых весов, соответствующей популярным и стоп-словам, линейность должна была быть искажена за счет того, что популярное слово используется в одном документе много раз.
Однако то, что искажений линейности нет, как бы говорит нам - что веса считаются даже не по документам, а по словоформам, и в качестве меры контрастности используется не IDF, а ICF.
Разные коллекции документов – разные веса
Так как при получении переформулировок в запросах часто присутствуют одни и те же слова, у этих слов я ожидал увидеть одинаковые же веса. Однако было большим удивлением увидеть разные веса для слова fizi в раздичных вариантах задания запроса:
| коллекция | вес слова fizi | пример запроса | запросов |
| русская | 61543020 | 1100694 | |
| англоязычная | 10427993 | mail.ru | 278056 |
| украинская | 113009721 | музика безкоштовно | 321 |
Таким образом, у одного слова может быть несколько разных весов – в зависимости от того, к какой области «приписан» запрос и по какой коллекции документов считается статистика по слову. Всего было видно три коллекции – основная русскоязычная (когда запрос содержал русские слова), англоязычная (когда запрос полностью состоит из цифр и английских букв) и украинская (?) (когда запрос состоит полностью из украинских слов).
Поскольку число документов и сами документы в коллекциях разные, относительная популярность одного и того же слова тоже получается разной. Максимальный вес тоже отличается для этих разных коллекций.
Примеры тематических переформулировок
Вот как переформулируются поисковые запросы по тематике продвижения сайта:
| запрос | переформулировка |
| продвижение сайта | ((продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208) &&/(-32768 32768) сайта::410) |
| оптимизация сайта | ((оптимизация::32653 ^ оптимизировать::95157 ^ оптимизироваться::4208069) &&/(-32768 32768) сайта::410) |
| поисковая оптимизация | ((поисковая::17483 ^ поисковик::65545) &&/(-32768 32768) (оптимизация::32653 ^ оптимизировать::95157 ^ оптимизироваться::4208069)) |
| поисковая оптимизация сайта | ((поисковая::17483 ^ поисковик::65545) &&/(-32768 32768) (оптимизация::32653 ^ оптимизировать::95157 ^ оптимизироваться::4208069) &&/(-32768 32768) сайта::410) |
| продвижение | (продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208) |
| раскрутка сайта | (раскрутка::42374 &&/(-32768 32768) сайта::410) |
| поисковое продвижение | ((поисковое::17483 ^ поисковик::65545) &&/(-32768 32768) (продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208)) |
| web продвижение | ((web::5561 ^ !!веб::8429) &&/(-32768 32768) (продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208)) |
| продвижение web сайтов | ((продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208) &&/(-32768 32768) (web::5561 ^ !!веб::8429) &&/(-32768 32768) сайтов::410) |
| заказать продвижение | (заказать::6844 &&/(-32768 32768) (продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208)) |
| поисковое продвижение сайта | ((поисковое::17483 ^ поисковик::65545) &&/(-32768 32768) (продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208) &&/(-32768 32768) сайта::410) |
| раскрутка оптимизация | (раскрутка::42374 &&/(-32768 32768) (оптимизация::32653 ^ оптимизировать::95157 ^ оптимизироваться::4208069)) |
| продвижение раскрутка сайта | ((продвижение::19047 ^ ((про::2793-движение::8030)) ^ продвигать::40288 ^ продвигаться::199208) &&/(-32768 32768) раскрутка::42374 &&/(-32768 32768) сайта::410) |
| продвижение сайта в поисковых системах | (продвижение::19047 &&/(-32768 32768) сайта::410 &&/(-32768 32768) в::51 &&/(-32768 32768) поисковых::17483 &&/(-32768 32768) системах::1143) |
Заключение
Польза от знания переформулировок запросов очевидна для поисковой оптимизации– использование дополнительных слов в текстах и ссылках, использование ограничения расстояний при оптимизации текстов страниц, использование «весов» слов для разбавления текстов ссылок.
Не все данные вечны, многие теперь нельзя получить с помощью открытых методов, но большая часть этих данных сохранена и может использоваться в seo-сервисах и системах автоматического продвижения.
Литература
- Сервис поиска переформулировок запросов в Яндексе по базе из 1.3 млн. запросов
http://tools.promosite.ru/use/perekoldovki.php - Сервис поиска «весов» слов в Яндексе
http://tools.promosite.ru/use/weight.php - Евгений Трофименко, доклад на конференции "Поисковая оптимизация и продвижение сайтов в Интернете" – 2008
http://promosite.ru/download/conference/ashmanov2008/ - Евгений Трофименко, доклад на конференции " Практика поискового продвижения сайтов. NetPromoter 09" – 2009
http://promosite.ru/download/conference/netpromoter2009/ - Синтаксис языка запросов Яндекса
http://help.yandex.ru/search/?id=481939 - Илья Сегалович, Михаил Маслов
Яндекс на РОМИП-2004. Некоторые аспекты полнотекстового поиска и ранжирования в Яндекс
http://romip.ru/romip2004/07_yandex.pdf - Расширение запросов - переходы из одной части речи в другую, транслитерация, аббревиатуры
http://webmaster.ya.ru/replies.xml?item_no=1030 - О смягчении фильтрации найденных документов
Подлетая к "Магадану"
http://webmaster.ya.ru/replies.xml?item_no=645 - Отмена показа переколдовки
http://forum.searchengines.ru/showthread.php?t=173853 - Курьезы переформулировок: окна и витрины
http://forum.searchengines.ru/showpost.php?p=7794206&postcount=128 - Евгений Трофименко
доклад на конференции " Практика поискового продвижения сайтов. NetPromoter 10" – 2010
http://promosite.ru/download/conference/netpromoter2010/
|
продвижение сайтов в поисковых системах трафик, позиции, прозрачность | |
| promo |
|