| promo |
|
| продвижение сайтов в поисковых системах трафик, позиции, прозрачность | |
Постановка экспериментов над поисковыми системами
Евгений Трофименко
22-23 ноября 2005
доклады
Доклад на конференции
"Поисковая оптимизация и продвижение сайтов в Интернете 2005", 22-23 ноября 2005
(файл)
Введение
Эксперименты над поисковыми системами в части исследования влияния ссылочных и текстовых параметров релевантности – важная составляющая жизни оптимизатора и напрямую влияет на доходы его клиентов. Эксперименты со ссылками проводить сложнее, а с тестами – проще, и именно знание особенностей расчета текстовой релевантности особенно полезно при сборе трафика по низкочастотным запросам. Низкочастотный целевой трафик составляет основу многих интернет-бизнесов, как оказывается, очень большую его часть.
По результатам исследований лог-файлов Яндекса [1], всего лишь 2.74% запросов в Яндекс являются «продвинутыми» (используют скобки, кавычки), и 0.88% являются булевыми (используют логические операторы), а основная масса запросов – фразы с средним числом термов 2.92-2.68.
Относительно большое число длинных запросов означает важность работы с низкочастотными запросами при продвижении в поисковых системах. Средняя длина запроса в 2.5 – 3 слова предполагает, что оптимизация текстов и кодов сайтов вовсе не собирается «умирать», поскольку по «длинным» запросам рационально продвигаться страничными факторами, а ссылочные задействовать в особых случаях.
Выработка идеологии постановки экспериментов
Вероятно, многие пробовали проводить эксперименты по выяснению различных параметров, влияющих на ранжирование сайтов в поисковых системах. Хотя само проведение экспериментов – увлекательное и развивающее занятие, от них все-таки нужен результат.
Чтобы такие эксперименты были удачными, желательно (как в науке) ставить эксперименты так, чтобы можно было сказать: «отрицательный результата – тоже результат». Это возможно тогда, когда в эксперименте изменяется, например, один фактор, а все остальные факторы, могущие влиять на ранжирование – остаются постоянными. Только сохранить их постоянными не всегда возможно…
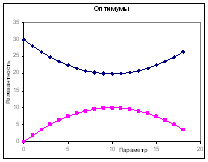
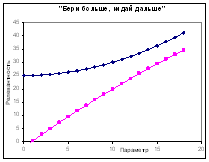
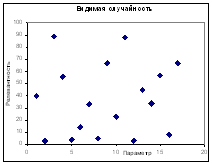
При постановке эксперимента нам всегда стоит предполагать, какого рода данные мы получим или можем получить в результате. Предполагая, что нам удалось выделить влияние одного из экспериментальных параметров на релевантность, мы можем получить такие типы зависимостей, которые могут комбинироваться друг с другом в разных диапазонах изменения «параметра»:
| «Оптимум» | «Бери больше, кидай дальше» | «Видимая случайность» |
|
|
|
|
Существование оптимальных значений параметра,
обеспечивающих максимум «хорошего» параметра или минимум «плохого».
Пример: Если на странице есть текст из 1000 слов, то размещение на ней одного целевого слова – будет недостаточно. Замена всех 1000 слов на целевые – слишком много. Следовательно, между этими числами есть оптимум. |
Увеличение параметра приводит к улучшению результата – не
обязательно линейному, но не выходящему на насыщение.
Пример: Ссылки с других сайтов – чем больше, тем лучше. Однако по массиву ссылок целиком могут существовать оптимумы (например, доля ссылок с ключевым словом – как показатель «накруток») |
Совершенно непонятная зависимость. Однако такое бывает, и
часто.
Можно предполагать отсутствие всякого влияния параметра в этом диапазоне. Стабильность этого результата во времени может определяться, например, внутренними (для ПС) идентификаторами страниц. Однако можно предполагать и влияние неких неучтенных факторов. |
Факторы, мешающие постановке экспериментов или искажающие результаты
Можно привести некоторые особенности работы поисковых систем, которые затрудняют постановку экспериментов над ними и интерпретацию результатов.
| Фактор | Что имеется в виду | Что делать (исключить влияние фактора) |
| Недостатки баз поисковых систем | ||
| Неполная индексация текстов и ссылок | Поисковик может проиндексировать не весь экспериментальный массив | Ждать. Лучше, если эксперимент будет «стационарным». Проверить, есть ли все нужные страницы в базе. |
| Ложные дубли | Есть работы [2] по методам поиска и фильтрации нечетких дублей, это стоит учитывать. Поисковиками декларировались цели разделить «обвязку» и «контент» страниц в расчете релевантности. | Не делать очень похожих друг на друга экспериментальных страниц |
| Быстрый робот (Яндекс) и выпадение сайта | В результате введения в строй «быстроробота» Яндекса [3], случаются неожиданные выпадения сайтов из его базы. | Не использовать больших экспериментальных сайтов и отключить поддержку IF_MODIFIED_SINCE |
| Недостатки выдачи | ||
| «Abort trap» (Яндекс) и «No Urlist» (Рамблер) | Ошибки выдачи, ошибка сервера, который «навешивает» сниппеты и урл на найденный id документа. | Ждать. |
| Выпадение кластеров (главных и внутренних страниц) | Временное пропадание из выдачи части страниц сайтов из-за того, что не отвечает один из серверов кластера поисковика | Ждать. |
| Найдено по ссылке | ||
| Ручные факторы | ||
| Бан сайта | Ручное удаление сгенерированного сайта из баз поисковиков, возможно, после визита автоматического проверяльщика или превышения трафика на сайт | Начать новый эксперимент |
| «Наложение непот-фильтра» | Неучет исходящих ссылок с сайта (ИЦ и ссылочного ранжирования) | Не попадаться. |
| «Пессимизация сайта» | Неучет входящих ссылок на сайт (включая ссылочное ранжирование), сопровождается падением тИЦ | Не попадаться. |
| Факторы времени | ||
| «Бонус новичка» и, наоборот, «sandbox» | Заложенное в алгоритм завышение позиций (влияния) для свежепроиндексированных сайтов и ссылок (Яндекс) или наоборот, занижение (Google) | Ждать. Лучше, если эксперимент будет «стационарным» |
| Учет даты индексации или изменения страницы | Новизна страниц декларируется поисковиками как положительный фактор, для определенности лучше учесть его влияние. | Либо ничего не делать, либо использовать небольшой экспериментальный сайт.. |
| Изменение алгоритма (его параметров) | Параметрами могут быть различные лимиты, относительные веса, могут вводиться новые параметры и пр. | Бывает редко. |
| Апдейты (ссылочные и текстовые) | Нестабильнось выдачи при «выкатывании новой базы» | Не снимать данные во время апдейта |
| Внестраничные и не-ссылочные факторы | ||
| Счетчики посещаемости (Rambler Top100) | Показания счетчика вместе с описанием сайта в Rambler Top100 используются вместе со ссылками для расчетов «коэффициента популярности» - показателя цитируемости в Рамблере | Если эксперимент не касается влияния счетчика – не регистрировать сайт. |
| Тулбары (Яндекс, Google) | Разработаны возможности для ручной оценки сайтов посетителями с Google Toolbar. У Яндекса тоже есть тулбар, об отслеживании действий посетителя ничего не известно. | Не приводить на сайт аудиторию, тем более с тулбарами. |
| Учет описания из своих каталогов и топов (Яндекс, Рамблер, Google) | Наличие сайта в определенной ветке каталога может (1) определять тематику сайта и (2) описание сайта в каталоге может играть отдельную роль в ранжировании. | Ничего. Вряд ли экспериментальный сайт добавят в каталог добровольно. |
| Учет кликабельности позиций выдачи | Учет реальных переходов пользователей на сайты при оценке «качества» сайта. Об использовании в рунетовских SE ничего не известно. | Не кликать и не использовать популярные слова в эксперименте |
| Переформулирование поискового запроса («Колдунщик» Яндекса, «Клей» Рамблера) | Колдунщик – это преобразование введенного пользователем
запроса в иной, который и передается искалке. Призван перевести запросы,
заданные на «человеческом языке», на нормальный язык [6,7]
В Рамблере пробелы и знаки препинания в запросах по-разному трактуются в зависимости от контекста как «клей» разного вида [8] |
Сама работа колдунщика – тема для экспериментов. |
| Дискретность | ||
| Дискретность выдачи | Многие параметры (частоты, веса, цитируемость) страниц могут быть рассчитаны как непрерывные, а позиции в выдаче дискретны – первый, второй… | Жить с этим. |
| Дискретность «весов» и ссылок | Хотя в алгоритме PageRank ранг страницы – величина непрерывная, учет текстов ссылок вполне может быть дискретен (например: вклад ссылки в ранжирование только при превышении некоего лимита важности ссылки) | Это отдельная тема для экспериментов. |
| Дискретность учета текстов (Яндекс) | Яндекс при расчете текстовой релевантности не учитывает все вхождения слов, а выбирает в соответствии со словосочетанием фразы-«пассажи», из которых затем выбирает значимые [4,7] | Пока не усвоена статья Ильи Сегаловича - ставить эксперименты с Яндексом по однословным запросам. |
| Разделители слов | После работы «колдунщика Яндекса» в запросе часто используются операторы расстояния в словах или предложениях и подвержены влиянию разделителей на поиск. В Рамблере есть учет разделителей слов [8] | |
| Частичная индексация полей | Есть эксперименты, показывающие ограничения по числу индексируемых слов в title [5], можно полагать, что подобное возможно и с другими полями (текстами ссылок). | Выяснение длины индексируемой части – тема для эксперимента. |
Взаимное влияние факторов
Взаимным влиянием различных факторов будем называть способ участия этих факторов в воображаемой «формуле расчета релевантности». Например, один из самых обсуждавшихся вопросов такого плана – «складывается» ли текстовая релевантность со ссылочной или «перемножается»?
Подобные вопросы становятся принципиальными при оптимизации и продвижении, при поиске «узких мест». Если факторы «суммируются» - их можно «оптимизировать» независимо друг от друга, или временно отставить один из них на будущее. Если же они «перемножаются», неоптимальность по одному из них сведет на нет результат всей работы.
Можно предложить к рассмотрению несколько схем взаимного влияния факторов:
1.Лимит. F=max(a,b)
Такой тип взаимного влияния,
скорее, надо назвать наоборот – отсутствием влияния. Эта схема может
использоваться, например, если страница оценивается с точки зрения наличия или
отсутствия на ней ключевого слова, и если в алгоритме не важно, сколько слов и
в каком поле (заголовках, текстах, тегах) страницы присутсвует.
2.Суммирование.F=a+b
Факторы дают свой вклад в общую
релевантность независимо друг от друга. В этой же схеме можно приписать разные
веса разным факторам. Например, влияние отдельных ссылок на релевантность
сайта.
3.Произведение.F=a*b
Улучшение обоих факторов сразу
приводит к гораздо большему росту результатов, чем сумма их эффектов. Например,
взаимное влияние текстовой и ссылочной релевантности.
Соответственно, при проведении экспериментов с одновременным изменением нескольких факторов нам придется принять некие гипотезы относительно их взаимного влияния. Кроме того, поисковые системы учитывают массу ссылок и оперируют сайтами, а не просто страницами. Поэтому стоит принять определенные гипотезы относительно взаимного влияния:
- Отдельных документов, образующих сайт, между собой
- Отдельных ссылок на сайт между собой
- Документов и ссылок на них
Но и при рассмотрении «ссылочной» и «текстовой» релевантностей отдельно нам стоит учесть возможное взаимное влияние отдельных факторов, из которых складывается каждая из них.
Факторы релевантности страниц
Перечислим некоторые наиболее очевидные страничные факторы, которые могут участвовать в расчете релевантности страниц сайта запросу.
- Количество вхождений ключевого слова или фразы в различные поля страницы (<title>, заголовки, тексты страницы, отдельные блоки текста, отдельные теги выделения, тексты ссылок, теги <meta>, alt...)
- Частота ключевого слова или фразы в различных полях страницы
- Близость ключевых слов к началу документа
- Различная относительная «важность» тегов
- Блочная структура страницы – ячейки таблиц, параграфы, предложения.
- Учет стоп-слов (с ними или без них?) при количественных расчетах параметров
- «Качество» страницы [11] – распределение частей речи («0.25 - 0.4 - 0.35» для глаголов, существительных и прилагательных, местоимений, предлогов и др.) в тексте страницы.
- Разнообразие употреблений ключевого слова (фразы) в каждом из полей страницы – использование различных падежей, чисел, времен глаголов и т.п.
- Разнообразный порядок слов в различных ключевых фразах на странице
С одной стороны, по каждому фактору отдельно можно провести хорошее исследование, зафиксировав остальные факторы. С другой стороны, если бы мы захотели проверить, есть ли взаимное влияние этих факторов, и мы взяли бы 10 вариантов каждого фактора – мы получили бы 10^9 страниц, которые было бы сложно приндексировать, почти невозможно выкачать выдачу по ним, и, кроме всего прочего, такое количество страниц обязательно обратит на себя внимание модераторов поисковых систем. А поскольку нам пришлось бы использовать сгенерированные тексты – эксперимент попал бы в бан. Для проверки взаимного влияния хорошим выходом была бы попарная проверка по избранным парам факторов.
Факторы ссылочного ранжирования
Если не вдаваться в расчеты весов ссылок (цитируемости) – эта тема находится за рамками доклада – предположим, что мы стараемся получать ссылки с хороших сайтов в меру сил. Факторы, которые могут участвовать в расчете ссылочного ранжирования, разделим на качественные и количественные:
- Веса страниц, с которых установлены ссылки (не можем контролировать и узнать)
- Различные способы расчета ссылочного ранжирования для внутренних и внешних ссылок
- Число ссылок с ключевым словом или фразой
- Способ учета весов ссылок:
- Учитываются ли веса вообще, или учитывается только наличие ссылки?
- Вес ссылки - непрерывный или дискретный?
- Есть ли нижний лимит на вес ссылки или нет?
- Вес ссылки учитывается как цитируемость ссылающейся страницы или как передаваемая доля цитируемости?
- Учет близости ссылки к началу документа (вариант: различный учет ссылок из «обвязочной» части страницы и «смысловой» части)
- Учет близости ссылки к соседним ссылкам (вариант: учет количества обычного текста вокруг ссылки) или отдельным элементам страницы (заголовкам)
- Разнообразие текстов ссылок (вариант: слияние нескольких ссылок с одинаковым текстом, если их количество превышает некий лимит, учет только части из них)
- Политика учета сквозных ссылок с сайта (учитывается только одна, учитываются только ссылки с разными текстами, учитываются несколько наиболее мощных ссылок)
- Политика учета обменных (договорных) ссылок (с одинаковым весом, с разными весами)
- По каждой из ссылок – учет текстовых факторов:
- Количество ключевых фраз в тексте ссылки
- Частота ключевой фразы в тексте ссылки
- Использование различных форм (падежей, чисел и т.п.) в тексте ссылки
- Различный порядок слов фразы в тексте ссылки
- По всей массе ссылок на документы сайта:
- Доля ссылок с ключевыми словами в общей массе
- Доля обменных (договорных) ссылок
- Разнообразие текстов ссылок (уникальность)
- Политика учета нескольких ссылок с одного документа на целевой домен (учитываются все ссылки, учитывается только одна (первая?) ссылка на документ, учитывается только одна ссылка на домен)
С одной стороны, в случае ссылок у нас получается гораздо больше вариантов учета ссылок при ранжировании. С другой стороны, каждая ссылка – это отдельный объект и маловероятно, что может существовать взаимное влияние ссылок, отличное от суммирования их эффектов.
Отдельные простые эксперименты
Некоторые эксперименты могут быть проведены и без специально созданного сайта – с помощью анализа выдачи поисковых систем.
«Колдунщик» Яндекса
Колдунщик служит для переформулирования поискового запроса пользователя. Первые сообщения о нем появились в мае 2001 года (http://www.netoscope.ru/news/2001/05/24/2385.html), около года назад [6] люди заметили, что перефразированный запрос передается «подсветчику слов» Яндекса. Поскольку в переформулированном запросе использовались параметры мягкости, как в [4], возникла мысль, что запрос в подсветке и является тем запросом, который отрабатывается вместо введенного пользователем. Кроме того, если ввести в поиск «переколдованный» запрос, он в неизменном виде переходил в «подсветчик».
Для того, чтобы посмотреть «переколдованный» запрос, надо найти в адресе ссылки «Найденные слова» параметрreqtext=, который содержит запрос с расстояниями и параметрами мягкости, а также парамерами, напоминающая «веса слов» в базе (величина, тем большая, чем реже в базе встречается это слово). Вот несколько примеров его работы:
| Исходный запрос | Переколдованный запрос | Комментарии |
| реклама в интернете | реклама::1676 & !+в::50 & интернете::1313 | Поиск в пределах одного предложения. Ненулевой вес предлога стоит рассмотреть вместе с тем, что предлоги стали подсвечиваться в Яндексе (раньше предлоги получали в колдунщике нулевой вес и не подсвечивались) |
| интернет-реклама | (интернет::1313 &/(1 1) реклама::1676)//6 | |
| интернет реклама | (интернет::1313 &/(-1 3) реклама::1676)//6 | Разная переколдовка слов с тире и без тире – разные расстояния |
| лоренциан | (лоренциан::2063133498 &/(0 0) !!%лоренциан::2063133498) | Поиск на нулевом расстоянии – усиление влияния одного слова? |
| напольные покрытия | (напольные::78746 &&/(-7 7) покрытия::21744)//6 | Поиск в пределах 7 предложений |
| новый год | (новый::532 &/(-1 3) год::502)//6 | Поиск в пределах нескольких соседних слов в одном предложении |
| что такое RTFM | RTFM::2063133498 &/(1 1) !%это::359 &/(-2 4) %означает::16316 &/(-2 4) %аббревиатура::334021 &/(-2 4) %расшифровывается::183623 | Добавление новых слов в поисковый запрос – более того, эти слова подсвечиваются в выдаче |
| аренда квартир | (аренда::10297 & квартир::5104)//6 | Поиск в одном предложении |
| квартир аренда | (квартир::5104 &&/(-3 3) аренда::10297)//6 | Поиск в пределах 3 предложений |
Алгоритм работы колдунщика может меняться – например, «реклама в интернете» раньше переколдовывалась как(реклама::1676 &/(-1 +3) в::0 &/(-1 +3) интернете::1313)//6. Работает колдунщик по-разному в зависмости от порядка слов в запросе, падежей и др.
«Клей» Рамблера:[8] пробелы и знаки препинания в запросе к Рамблеру в зависимости от контекста заменяются на различные «кусочки клея» - операторы поиска в заданных пределах, обладающие заданными свойствами «растягиваемости» и «сжимаемости». Т.е., работает алгоритм, похожий на «колдунщика», но результаты его работы не показываются.
Разделители слов и использование подсветки
Поскольку каждый запрос обслуживается «колдунщиком», важно знать, как определяется граница предложения, т.к. если в переколдованном запросе есть операторы поиска внутри одного предложения, а целевые слова находятся в разных предложениях, фраза не не будет учтена. Поскольку «подсветка» подсвечивает только слова, вошедшие в пассажи, можно выяснить, какие именно слова учитываются и какие разделители слов считаются концом предложения.
Эксперимент: находим одну из проиндексированных страниц своего сайта по целевому запросу, который переколдовывается с ограничением на одно предложение. Меняем текст страницы, вставляя разные разделители и смотрим через подсветку – если слова не выделяются, значит, разделитель является маркером конца предложения.
Результат: Разделителями предложений являются: теги <td>, <div>, <h3>, <br> всегда, и при условии, что второе слово после разделителя идет в верхнем регистре – точка, многоточие, восклицательный и вопросительный знаки, и двоеточие. В случае, когда после разделителя слово идет в нижнем регистре – слова считаются как в одно мпредложении. [10]
Используя «подсветчик», можно также определять, какие слова из запроса ( «пассажи») были отобраны и учтены Яндексом при ранжировании данной конкретной страницы.
Длина индексации в тайтле (Яндекс)
В [5] показано, как Яндекс индексирует первые 24 слова в заголовке.
По запросу в поле <title> с расстоянием в 23 слова: $title(работа &/+23 работа) находятся документы, в title которых есть слова «работа» на расстоянии и больше 24 слов друг от друга, однако по запросам с расстоянием больше 23 слов они не находятся: $title(работа &/+24 работа).
Конечно, это могло быть связано и с ограничениями на «поиск с расстояниями», однако по фразам из «далекой части» title эти страницы тоже не находятся.
Правда, есть опровергающий пример (с индексацией 65 слов в тайтле), но он всего один и на других страницах не воспроизводится. Страница находится по запросу $title(агентство &/+62 работа) и отличается отсутствием знаков препинания в title.
Поскольку в данном случае используется оператор с расстоянием в словах внутри предложения, надо отделять ограничение на индексацию title и ограничение на длину предложения.
Простые теги
Какое выделение слова более важно для поисковика, какое менее? Иногда подобные эксперименты необязательно и проводить – достаточно обратить внимание на выдачу. Например, движок конференции White Tiger Board (WTB) помещает полный текст поста в тег <textarea> на странице ответа на пост– и такие страницы неизменно всплывали в Яндексе выше обычной страницы с текстом поста.
Оптимально проводить эксперимент с одинаковым текстом (или хотя бы одинаковым распределением частей речи по тексту), одинаковым числом стоп-слов, одинаковой близостью ключевого слова к началу. И, это важно: текстом достаточной длины – если он будет коротким, результаты могут оказаться «случайными» (в Рамблере, например)…
Пример эксперимента: [8], 4 страницы, уникальное слово в тегах <strong>, <b>, <em>, <i>, тексты на страницах разные, размер текста– 1 средний (?) абзац. В выдаче страницы выстроились в приведенном порядке.
Простые ссылки (2005, ноябрь)
Эксперимент: Ссылка с сайта 1 (PR=4, тИЦ=250) с текстом уникальной абракадабры (буквы A-Z и цифры) установлена на главную страницу другого сайта 2 (на котором нет этого слова). Поиск проводился по тексту абракадабры. На странице ссылающегося сайта 310 слов, ссылка в низу страницы.
Google: 1й – «302 редирект» с одного из каталогов на ссылающийся сайт, 2й – ссылающийся сайт, 3-7 – украденная скриптами главная страница ссылающегося сайта, 8й – сайт, на который ссылаются
Rambler: 1й – страница ссылающегося сайта, сайта 2 нет.
Yandex: 1й –сайт 2 (на который ссылаются) с описанием словами «текст ссылок: », 2й – ссылающийся сайт.
Простые частоты в Яндексе (2003)
Эксперимент: использовано 100 документов, сгенерированных из исходного связного текста из 2400 слов, отдельные слова заменялись на ключевое слово так, что частота слова менялась от 0 до 10% с шагом 0.1%. Маска замены наследовалась – следующий документ создавался из предыдущего. Стоп-слова никак не контролировались. Близость к началу документа не контролировалась. HTML-разметки не было. Выдача Яндекса взята из поиска страниц внутри сайта (фрихостинг, домен 3 уровня) по запросу из одного слова.
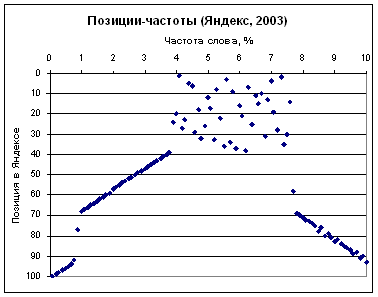
Здесь видно, что в диапазоне 4-7.5% мы имеем случайное распределение позиций по частотам, затем идет группа документов с частотой от 4% до 1%, затем – от 7.5 до 10%, самыми нерелевантными оказались документы с частотой ключевого слова от 1% и ниже.
Вывод: использовать частоты в диапазоне 4-7.5%
Простые частоты в Рамблере (ноябрь 2005)
Эксперимент: Экспериментальный сайт представляет собой новостной сайт из ~36 – 38 тыс. страниц с осмысленными текстами, содержащий разные виды «обвязки» текста новости (3 варианта: фиксированный текст до новости, после носовти, промежуточный), разные алгоритмы формирования title (4 варианта), разные алгоритмы формирования H1 (3 варианта), итого 48 вариантов, по ~700 страниц в каждой группе.
В «обвязочном» тексте (длиной 20 символов) использовано одно несуществующее слово. Данные получены скачиванием выдачи Рамблера по этому слову по страницам внутри домена. В текстах новостей слово не встречается.
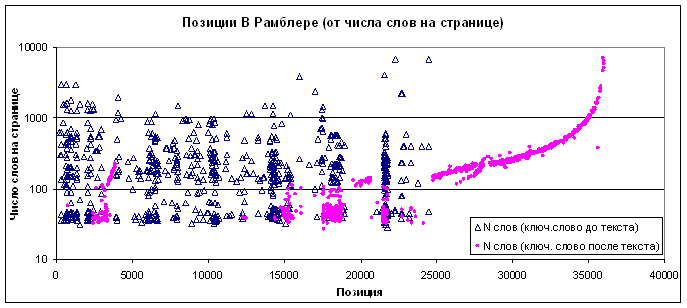
Выбрано 2 группы страниц – с текстом обвязки до и после текста новости. Частота слова – 1/N, на диаграмме изображена позиция в выдаче и число слов на странице N. Новостей короче 10 слов не было. Число слов в title и h1 не контролировалось.
Ситуация характерна для всех пар групп. В случае, когда ключевое слово находится после основного текста, упорядочение по убыванию «частоты» начинает работать только если общее число слов в новости – больше 100, если число слов меньше 100 – распределение «случайное». В случае, когда ключевое слово находится до основного текста, распределение «случайное» во всей области.
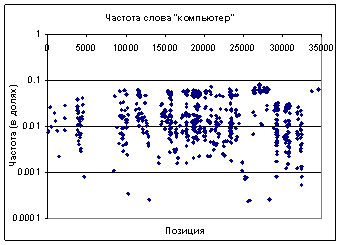
Число слов в документе в Рамблере (ноябрь 2005)
Экспериментальный массив– тот же, выбрана выдача по нескольким группам страниц. Все страницы содержат хотя бы одно слово «компьютер» (в разных падежах и числах) в тексте страницы и не содержат его в title и h1. Не контролировалось количество слов в title и h1. Рассчитана частота слова в тексте:
| Кажущаяся случайность | В которой все-таки есть порядок |
 |
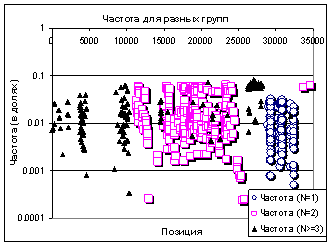 |
| Сначала складывается впечатление, что позиция сайта не зависит от частоты и распределение случайное. | Возможно, там и есть случайность, но есть и порядок – если выделить несколько групп страниц по общему количеству ключевого слова в тексте (1, 2, 3 и более), станет виден порядок следования групп. |
Во многих «случайных» распределениях можно найти порядок.
Ограничение эксперимента: приближение к реальности
Предположим, вы провели эксперимент по выяснению оптимального числа и частоты ключевого слова в title страницы. И в результате эксперимента выяснилось, что два употребления ключевого слова – лучше, чем одно. А три – лучше, чем два. А четыре, пять употреблений ключевого слова – еще лучше! Но самое лучшее – шесть (а большее число в эксперимент не входило).
Но в любом случае встают практические вопросы – как применять результаты эксперимента? Будете ли вы по результатам эксперимента создавать заголовки из 6 ключевых слов подряд? Вряд ли – бан еще никто не отменял, да и выглядеть в выдаче такой заголовок будет плохо, а значит, сайт будет недополучать посетителей. Будете ли вы ставить 10 тегов <h1> с ключевым словом на страницу, если эксперимент покажет, что это улучшит позиции сайта? Будете ли вы избавляться от существительных и дополнительно накачивать текст прилагательными и глаголами в описании товара в каталоге товаров?
Установив заведомо применимые для себя границы, провести нужный эксперимент гораздо проще. Например, выяснить частные вопросы – где лучше употреблять ключевое слово – в конце тайтла, в начале или в середине и сколько раз – один или два? А в заголовке h1? Сколько слов выдавать в «кратких описаниях» товаров на странице каталога, чтобы поддерживать частоту ключевых слов в заданных пределах? Все эти вопросы станут решаемыми при принятии разумных ограничений.
Ссылки
- Н.Е. Бузикашвили. Поисковое поведение пользователя Яndexа
(анализ веблогов)
http://company.yandex.ru/grant/2005/02_Buzikashvili_103035.pdf - Илья Сегалович. Как работают поисковые системы
http://company.yandex.ru/articles/article10.html - Сообщение в блоге Яндекса
http://company.yandex.ru/blog/index.xml?&msg=100026&month=8 - Илья Сегалович, Михаил Маслов. Яндекс на РОМИП-2004.
Некоторые аспекты полнотекстового поиска и ранжирования в Яндекс.
http://company.yandex.ru/articles/romip2004.xml - Форум seochase.com.
«Как Яндекс индексирует заголовок <title>?»
http://seochase.com/viewtopic.php?p=27150 - Евгений Трофименко, обсуждение «колдунщика Яндекса»
http://blog.promosite.ru/comments.php?142 - Козлов Игорь, обсуждение статьи [4] «Алгоритм Яндекса -
"поиск" и ранжирование документов»
http://www.minich.ru/business/seo/ - В. Шабанов. Сообщение «Язык запросов: изменения в семантике операторов»
http://groups.rambler.ru/groups/rambler.rambler.search/977573.html - Константин Рощупкин, сообщение в блоге
http://blog.seotext.ru/exp/163 - Разделители предложений при подсветке по запросу «интернет маркетинг»
http://promosite.ru/articles/se-work/report-optimization-2005-sample.htm(нижняя часть страницы) - Андрей Коваленко (Keva), сообщение на форуме
http://forum.searchengines.ru/showthread.php?t=1204 - База эксперимента с мануалом (около 4Мб) будет находиться по адресу:
http://promosite.ru/articles/se-work/report-optimization-2005-base.zip
|
продвижение сайтов в поисковых системах трафик, позиции, прозрачность | |
| promo |
|